犬ロボットと強化学習の欲望
昔、Gazeboでロボットを動かしていたけど、もっと楽に強化学習させたい!今流行りのディープな強化学習でバーチャル空間でロボットに歩行を学習させて、ある程度学習できたら実機のロボットがちゃんと滑らかに歩けるようにしたい!ロボットの歩行モーションはもう作りたくなーい!
ということで、「犬ロボットを歩かせる」シリーズを始めたいと思います。
第一回は、強化学習を仮想空間内でバリバリやるための環境作りから。 Unityで機械学習させるためのエージェントであるml-agentsを使います。 ついでにUnityも初めて使った素人なので、Unityの使い方もなんとなく学習していきます。
なんで仮想空間内で学習されるかというと、強化学習で学習するためには何万ステップもの試行が必要なのですが、そんな回数やったら実機が何期あってもたらないのです。でも仮想空間内のロボットは壊れないし、バッテリも減らないし、ポジションを戻すのも簡単。ある程度学習ができたら現実世界でもちょっと慣らす、というアプローチが良くとられております。
ボールのバランスを取るサンプルを動かしてみる
まずはUnityとml-agents使い方から慣れていきましょう。
ウルトラわかりやすいGetting Startedがあるので、こちらを参考にしてやると簡単にできます。↓
Getting Started with the Balance Ball Example
Once the training process displays an average reward of ~75 or greater
ということで、rewardが75以上になればOKみたい。
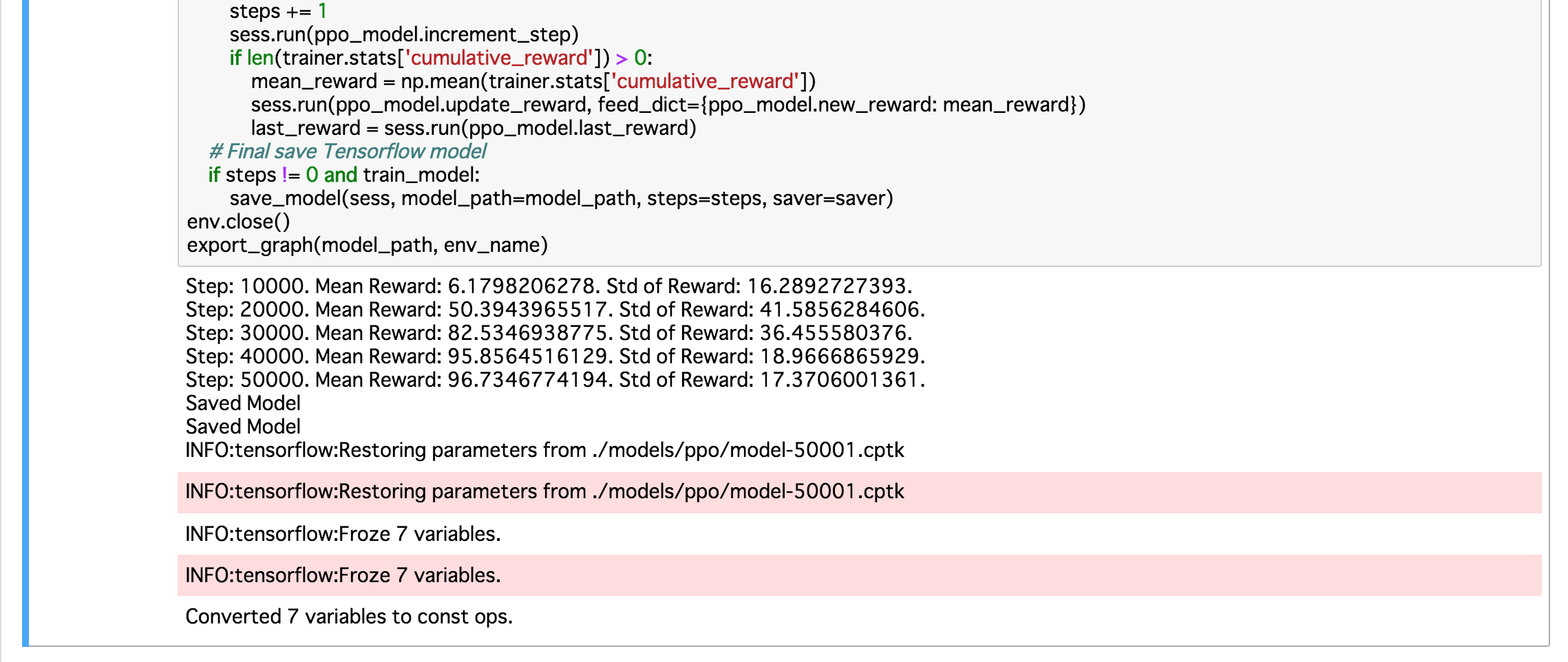
注意点としては、python/PPO.ipynbのデフォルトのパラメータではaverage rewardが75をなかなか超えないし、安泰しない。1時間ほどかかって500000ステップ終わってもボロボロボールこぼす始末です。
さらっとGetting Started内に書いている
(optional) In order to get the best results quickly, set max_steps to 50000, set buffer_size to 5000,
and set batch_size to 512. For this exercise, this will train the model in approximately ~5-10 minutes.
を参考にパラメータを修正したら、本当に5分で学習完了。50000ステップでreward 96.7を叩き出してくれた! (当方、MacbookPro Late 2013使用)
このあたりが「ハイパーパラメータ」といって、良くはわからないですが、ハイパー重要なパラメータなんだろう。ディープなニューラルネットワークが調整できない部分をヒトが調整しないといけないのかな〜。
あと、PPOというのはProximal Policy Optimizationの略で、どうもOpenAIの標準強化学習アルゴリズムらしい。 このへんもあとで出てきそうなのでメモ。
意外とちゃんとそれっぽくできた。
調子に乗って、tensorboardも見てみよう。
tensorboard --logdir=summaries
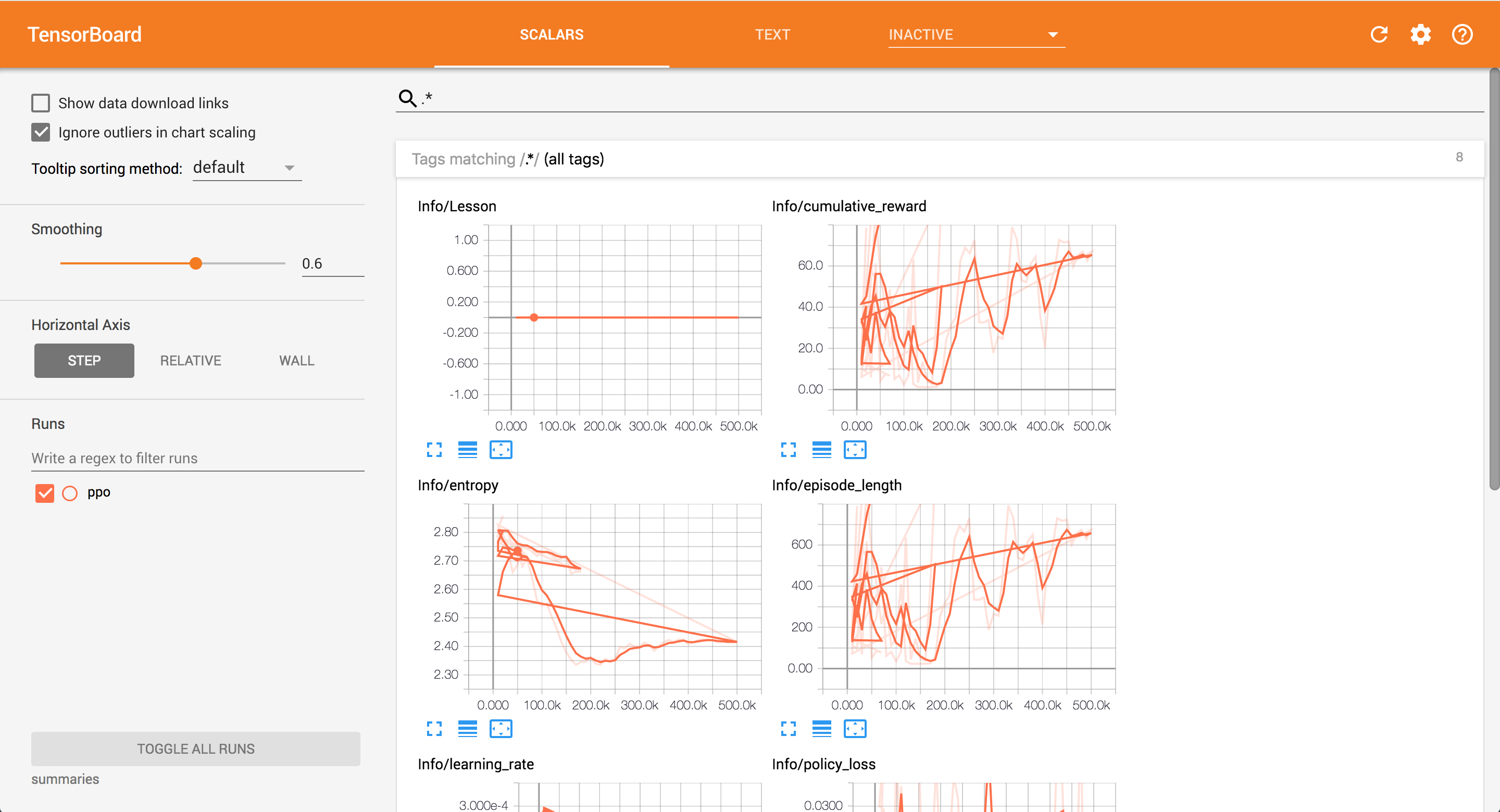
…よし!
次は独自モデルをUnity内で学習させる!そのための犬ロボットのモデルを適当に作ってみよう。