歩く前にひっくり返らせてみる
いろいろあって、歩かせる前にひっくり返るモーションの獲得から試してみることに。
前回 Unityで犬ロボットのサーボモータを動かすことができるようにしたので、今回はPPOで強化学習できるようにAgentのコードを書いていきます。
Dog の構造変更
その前に、Agentで両足のサーボを制御しやすいようにコードを変更します。

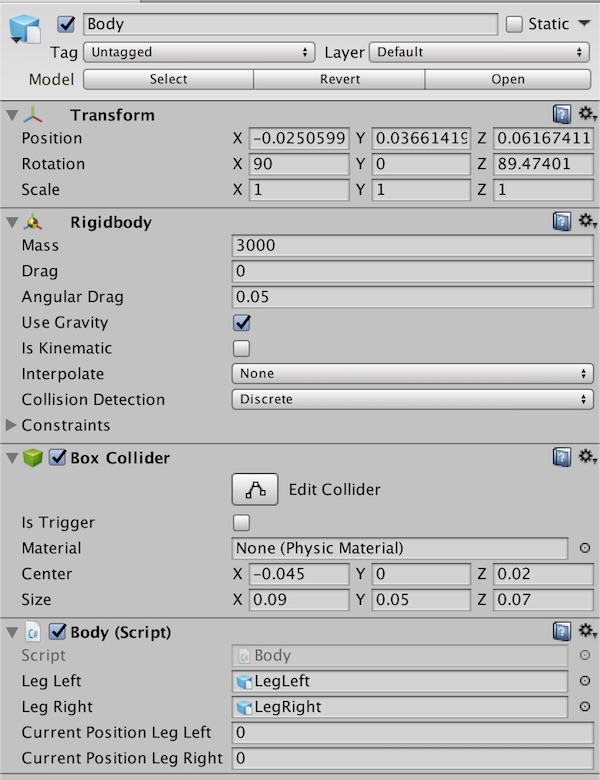
Body から LegLeft, LegRight の角度を制御できるようにして、Agent から Body を通して両足の角度を指定できるようにします。
Body のInspectorは以下のような感じに。
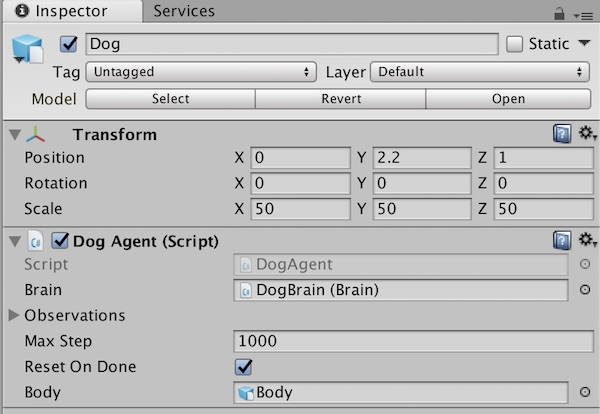
Dog に Agent をつけます。
Body.cs と DogAgent.cs は以下のようになりました。
変数モニターを導入
Using the Monitor を見つけた。
Monitor.Log(key, value, displayType , target)
これで指定した対象に棒グラフなどで変数をリアルタイムでモニタすることができるようになります。
今回は CollectState 内で状態を設定するタイミングでモニターに出力するようにしています。
Monitor.Log ("LegLeft", b.currentPositionLegLeft / 90.0f, MonitorType.slider, body.gameObject.transform);
左右のサーボ角と報酬を表示してみました。

犬ロボットを複数並べる

Dog をコピーして16個のDogを等間隔に配置し、マルチエージェント構成で学習を並列で行えるようにします。
この状態にしてから、Brain の Brain Type を External にし、 Build して Dog.app を生成して python ディレクトリにコピーします。
学習させる
ppo.py を実行してUnityアプリケーション上で学習させてみましょう。
python ppo.py Dog --train --normalize
--save-freq (デフォルト: 50000) で指定したステップごとにモデルが保存されるようになっています。途中で学習スクリプトを止めてしまっても、 --load を指定すると保存されたモデルから続けてくれます。
python ppo.py Dog --train --normalize --load
以下が10000ステップくらいの動き。
足は動いているけど、ひっくり返りそうでひっくり返られない状態。

1000000ステップ学習後。
私のMacBookPro(Late2013, 16GB, 2.8GHz)で数時間かかります。
ひっくり返ることができるようになっています。ひっくり返り方もたまに違うところがかわいい。

いろいろ報酬の構成を変えて最終的にネガティブ報酬がキツめになっていますが、Environment Design Best Practices を見ると、希望するアクションをしたらポジティブ報酬にしたほうがよいみたい。次回はそうしよう。
なんと、ML-Agents のv0.3が出たようです。
ML-Agents v0.3 Beta released: Imitation Learning, feedback-driven features, and more
模倣学習やマルチブレイン構成など、魅力的な機能追加がなされています。
次はv0.3にアップデートしてから、作りかけの犬ロボットを前進モーション獲得に挑戦してみます。